
Data Science Course data science course in noida know-how and synthetic Intelligence are the fields which can be penetrating many businesses and industries all over the world. The relationship between data science and AI become mounted thru the facts scientists. Earlier days, data scientists work become to isolate and basically for R&D studies purpose, but in a while, the scientists moved to the new improvements of artificial intelligence. It enables a lot for them to invent many new assets & matters which might be beneficial for human beings. The way of coping with different things are changing in keeping with the technology. The programming languages, cloud computing, and open-source libraries help a lot in making organizing activity simpler.
Facts technological know-how: Facts technology is an area where it can gain statistics and insights which are something of a cost. Records technological know-how is developing so fast and has shown various possibilities of spreading that has crucial to recognize it. Its miles an interdisciplinary area gadget and system to extract knowledge from the statistics in lots of forms. Synthetic Intelligence: Synthetic Intelligence is the period that makes an opportunity for machines to research from the experience. AI is different from robot automation, hardware-driven. AI can perform excessive-quantity, frequent, automated obligations without weariness. In other words, artificial intelligence dumps huge information to clear the objectives. The relationship between synthetic Intelligence and records science: best data analytics training in noida is the sector of interdisciplinary systems wherein it observes facts from data in numerous forms. It is also used to alter and to build Artificial Intelligence software program if you want to acquire the specified records from the large data sets and facts clusters. Information-oriented technologies like Hadoop, Python, and square are covered through the use of data technology. Facts visualization, statistical evaluation, dispensed architecture are the massive uses of information technological know-how. Whereas synthetic Intelligence represents an action plan in which it starts from the belief which leads to making plans action and ends with the feedback of notion. The information science plays a prime role wherein it solves specific troubles. As we discussed within the first step facts science identifies the styles then finds all of the viable solutions after which subsequently choose the first-class one. Both artificial intelligence and data technological know-how are the fields from pc science that penetrate numerous businesses all over the global. Their adoption corresponds with the huge-information upward thrust in the past 10 years. In recent times the superior statistics analytics can rework groups recognize organize a hobby, insights and create price. Development with open source libraries, cloud computing, and programming languages has additionally made it very simple to get effective records. Facts technology produces insights: Information technology's goal is to attain the human one especially i.e. to acquire perception and know-how. The very conventional definition of data science is that consists of a combination of software program engineering, records and domain knowledge. The principle difference between AI and statistics technology is that facts technology always has a human in the loop: someone seeing the discern, knowledge the insight and profiting from the realization. This statistics technology definition can emphasize: 1. Visualization 2. Test layout 3. Statistical Inference 4. Verbal exchange 5. Area information Facts scientists report possibilities and based on the square queries they can make line graphs with the aid of the use of easy equipment. They could build interactive visualizations, examine trillion information and increase the strategies of records. The primary aim of records scientists is to get a better know-how of data. Artificial Intelligence produces actions: Artificial Intelligence is the most widely diagnosed and older than the facts technology. As a result, it is the hardest one to outline. This term is surrounded through reporters, an extremely good deal of hype, startups, and researchers. In some systems, synthetic intelligence includes: 1. Optimization 2. Reinforcement gaining knowledge of 3. Robotics and manage theory 4. Robotics and control idea 5. Sport-gambling algorithms 6. Herbal language processing Right here, we've got to discuss one greater time referred to as deep studying. Deep learning is the system wherein it makes the straddle of both fields synthetic Intelligence and device getting to know. The use case is that training on precise and to get the predictions. However, it takes a large revolution within the algorithms of sport-playing. That is indifference to the previous sport gambling structures. As an instance Deep blue, which concentrated more on optimizing and exploring answer future area. Enterprise and Social impacts of records technology and synthetic Intelligence: As we mentioned above the field of data science training in noida is one of the traditional modes to locate how state-of-the-art and contemporary technologies are getting used to clear up commercial enterprise troubles in phrases of strategic gain. Records scientists will conduct their commercial enterprise as IoT, cloud continue and set of rules economics inside the close to future. These kinds of are to emerge as an influence throughout international enterprises. The underneath is the features of AI-Powered statistics technology: Computerized analytics techniques Analytics' structures domain specialization Predictive analytics There are many innovations are happening across industries everywhere in the world. Computer systems are studying to perceive the styles that are too massive, too complex, and too subtle for software and also for humans. We have witnessed over the previous couple of years that synthetic Intelligence playing a main role within the present technology. AI has the capability of reworking many organizations and they can create new kinds of corporations. Infosys in its survey record said that the maximum of the synthetic Intelligence businesses was predictive evaluation and large automation. AI can deliver blessings like development, right customer support, management, enterprise intelligence, and many others. Below are the foremost use cases for AI in the commercial enterprise: Sample popularity- Enhance commercial enterprise technique Business perception- Enhance performance with the aid of the usage of task automate functions Other than the advantages, AI has some hazards like highly-priced, time taking, desires to be included, and may also disrupt personnel. Information technological know-how is termed as the name of the game sauce wherein it complements the enterprise with the aid of driven-data. The tasks of records science can be investment multiplicative returns each from product demand insight steerage. The key aspect of hiring a facts scientist is to nature and interact with them first. Autonomy needs to accept to its architects to solve problems. While within the case of synthetic Intelligence it is the sensible sellers' layout in which the movements can maximize the achievement possibilities.
1 Comment
Page 1 of 3Part II of our look at data takes us into more sophisticated structures that are fundamental to computing - stacks, queues, deques and trees. If you don't know about these four then you are going to find programming tough and you will have to reinvent the wheel to solve otherwise simple problems.
This is a beginners informal introduction to some of the common data structures. Think of it as the least you should know about data structures with a few comments about object oriented programming along the way - but the main focus is on data. Data, the boring part of computing! Of course I for one don’t believe this common view of this major component of every application and computer system. Many view data as something that programs simply shovel from one place to another, occasionally changing it on the way. Even though this view admits that programs are about manipulating data, and hence important, I don’t think that this goes far enough. The traditional view is that a program is an equal mix of commands, the verbs, and data, the nouns. An alternative and more modern view is of data and commands mixing together in a smooth blend that produces a “mechanism”, a “model” if you like, of something that does a job. Yes, you’ve guessed it, I’m taking about object-oriented programming but my excuse is that there really is no other sort! (With apologies to functional, logic and other types of programmer who might be reading this.) To paraphrase a well known quote: any sufficiently sophisticated form of programming is going to be indistinguishable from object-oriented programming… Ok I'm partly joking as there are other approaches to programming but none so all pervasive and accepted. If you want to know more about the connection between objects and data structures then see Data Structures Part I - From Data To Objects. What does all this mean? When you first start to program you learn about variables, then arrays, and then if you are lucky you learn about structures or records. After this what you learn is very variable – pun intended… The art of programming beyond this simple beginning depends on inventing, or should I say reinventing, sophisticated data structures. The problem is where to begin and the general consensus is that the stack is where it’s at. The stackA stack is exactly what it sounds like. Make a stack of cards, say, on a table and you have everything you need to know about a stack. What are the basic stack operations – you can put a new card on the top of the stack and you can take a card off the top of the stack. As long are you aren’t cheating and dealing from the bottom (that would make it a data structure called a deque - see later) putting something on the top and taking something off the top are the only two stack operations allowed. Usually these two operations are called “push” and “pull” or “push” and “pop” but what you call them doesn’t really matter as long as you understand what is going on. Source 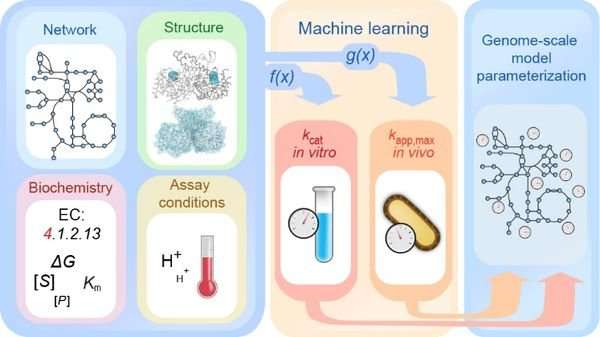 Bioinformatics researchers at Heinrich Heine University Düsseldorf (HHU) and the University of California at San Diego (UCSD) are using machine learning techniques to better understand enzyme kinetics and thus also complex metabolic processes. The team led by first author Dr. David Heckmann has described its results in the current issue of the journal Nature Communications.
Source NEW DELHI: To enhance cybersecurity skills and develop standards for talent development within India, National Association of Software and Services Companies (Nasscom), the Data Security Council of India (DSCI) and security software company Symantec launched National Occupational Standards for ten cyber security job roles on Monday.
They also launched qualification packs (QP), developed in consultation with organizations in sectors such as IT/ITeS, financial services and consultancy adv .. Read more at: utm_source=contentofinterest&utm_medium=text&utm_campaign=cppst “Building the next generation of cyber professionals is key to securing India’s critical information infrastructure, battling cybercrime and making the ‘Digital India’ initiative successful. As the global leader in cyber security, Symantec partners closely with governments and law enforcement agencies around the world," said Sanjay Rohatgi, Senior Vice President, Asia Pacific and Japan, Symantec. Enterprises in India faced more than 2.6 crore cyber threats during the third quarter of 2018 -- translating to over 2.8 lakhs threats every day, according to a new report from Seqrite, the enterprise arm of global IT security firm Quick Heal Technologies. Information technology (IT) and IT-enabled services (ITeS) companies faced the most number of threats, with over 40 per cent of the threats targeting the industry, according to the "Seqrite Quarterly Threat Report Q3 2018" on Wednesda .. We don’t propose to rationalize or harmonize digital, which in a very broad sense all of us know. So we won’t come out with a rigid and rigorous definition for digital which cannot be applied because it is not practical,” said R. Chandrashekhar, president, Nasscom. Nasscom’s position is significant because until now most equity and industry analysts and executives at IT firms have expressed hopes for a standard definition. India’s $154 billion IT outsourcing sector faces twin challenges in slowing growth and declining profitability as traditional solution-offering work such as application development and infrastructure maintenance gets commoditized. Source  Developed at the University of California, Berkeley in 2009, Spark is a powerful cluster-computing engine known for its fast, in-memory, large-scale data processing capability. Spark was acquired by the Apache Software Foundation in 2013 and is currently available as open source technology. In addition to the capability it offers, Apache Spark provides APIs in multiple programming languages, hence its flexibility for business applications across multiple industry verticals.
This article identifies five important trends that indicate the acceptance, adoption, and application of Apache Spark we can expect over the next few years. Trend #1: The shift from storage to computational power The era of data warehouse modernization was driven by large organizations focused on distributed storage mechanisms using Hadoop. Recently, businesses have started to focus their attention on deriving value from data analysis on big data (thereby translating data into actionable insights that provide a competitive advantage). As a result, processing power or RAM dedicated to analyzing data has begun to outpace the resources dedicated to storing data. Spark, with its large-scale, in-memory data processing capability, is at the center of this smart-computation evolution. We should expect to see significant growth in Spark investment, especially in highly competitive industry sectors such as financial services, manufacturing, and pharmaceuticals. Trend #2: Improved cloud-based infrastructures Organizations employ Spark to leverage its rapid innovation cycles fueled by contributions from the open source community. It is significantly faster to upgrade to newer versions of software in the cloud than it is for any on-premises implementation. One way for organizations to get up and running quickly on Spark is to utilize cloud-based implementations. However, this has been a viable option only for smaller companies and start-ups whose data volume was small. For enterprises with sizable data volumes or investments in large data centers, moving their data into the cloud was expensive. Larger organizations opted for a hybrid strategy where a cloud implementation of Spark was used to analyze streaming data while an on-premises Spark cluster was used to analyze historical and aggregated data. The cloud infrastructure has improved significantly in the last few years with considerable investments from Amazon, Google, and Microsoft. Scalability, elasticity, and ease of use are the pillars of the mainstream cloud infrastructure. Migration to the cloud has never been easier. Based on these cloud infrastructure improvements, even organizations with large data volumes may now adopt an entirely cloud-based Spark implementation. This would result in a more widespread adoption of Spark. |

 RSS Feed
RSS Feed
